
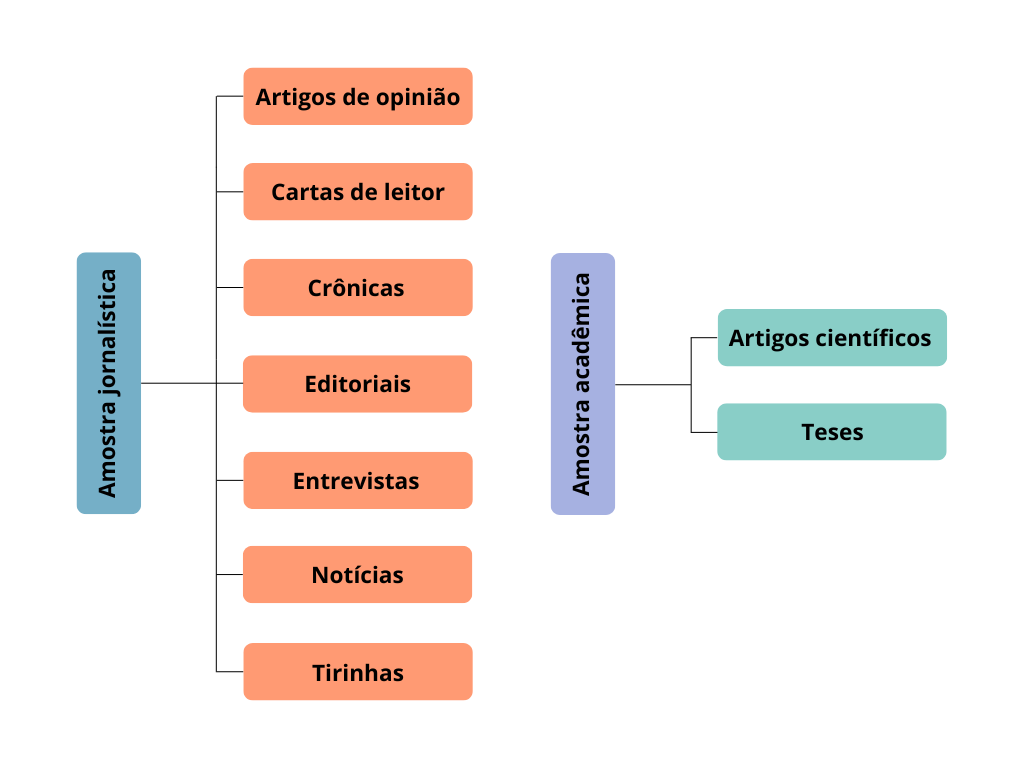
O corpus Pró-norma plural foi estratificado segundo duas variáveis sociodiscursivas: domínio e gênero textual-discursivo. No que tange à primeira, o corpus privilegiou os domínios jornalístico e acadêmico. Quanto aos gêneros jornalísticos, foram selecionados artigos de opinião, cartas de leitor, crônicas, editoriais, entrevistas, notícias e tirinhas. Já para o domínio acadêmico, foram coletados artigos científicos e teses. O organograma a seguir sistematiza os gêneros de cada domínio discursivo:
Para a composição do corpus, estabeleceu-se uma quantidade aproximadamente igual de palavras para cada gênero textual. No caso dos gêneros do domínio jornalístico, buscou-se atingir em torno de 20.000 palavras e, no que corresponde ao domínio acadêmico, em um primeiro momento, em torno de 7.000 palavras. Essa decisão explica a variação no número de textos representando cada gênero, que se deve à diferença no volume textual entre eles. Em relação à autoria, priorizou-se a inclusão de textos escritos por indivíduos associados ao estado de cada amostra, sempre que foi possível controlar esse aspecto. Por exemplo, no caso das teses, selecionaram-se somente aquelas escritas por autores que concluíram algum nível de pós-graduação em instituições situadas no respectivo estado.
Há um arquivo em .doc e outro em .txt para cada texto, a fim de tornar o corpus legível/manipulável por computador e, assim, facilitar a leitura em programas de busca automática.
Informações específicas sobre os textos que compõem cada amostra – título, autoria, data de publicação, número de palavras, entre outras – podem ser acessadas nas respectivas planilhas de metadados.